If you’re dealing with product data (orders, resources, SKUs, apps), chances are you need to work with auto-incrementing IDs, typically as a primary key or part of a composite one. Getting these to work can be pretty annoying, especially when you consider that major SQL dialects – Postgres, MySQL, and MSSQL – all handle syntax very differently.
This guide will walk through how to implement and work with auto-incremented fields in SQL, run through syntax for different SQL dialects, and explain how to handle more secure UUIDs.
Imagine you’re working with product data for the inventory of a new solar panel manufacturer and distributor. You need to create a unique item_number for each order placed from today on (think: thousands of orders). Item numbers cannot be duplicated in order to distinguish between each item in your inventory. If you’re creating these primary keys as a composite of table column values, your work is likely slow and cumbersome. You don’t have to suffer. There’s a better way.
When you use auto-incremented fields to assign integer values in your databases, you improve your database stability, limit errors caused by changing values, improve performance and uniformity, increase compatibility, and streamline validation. You can then use auto-increment in SQL queries to assign values in the primary key column automatically.
In short: you make your life—and database management—easier. In the example throughout this article, your table will need to include the following fields:
item_number: generated using auto-incrementitem_type: manually entered as a variable stringitem_category: manually entered as a variable string, tooitem_name: also manually entered as a variable string
These values will be used to reference products in internal databases that will need to be pulled when customers place an order.
Before we jump into syntax and our example, we want to take a minute to talk about why you should use auto-increment in your database (especially for primary keys). (If you just want to get to the point, click here to jump down to the syntax summary.)
Using auto-incrementing IDs in SQL brings with it a lot of benefits, chief among them saving a bit of your sanity. But it also helps you:
- Retrieve data faster and easier because each primary key is a simple, sequential integer rather than a complex mix of other string values.
- Avoid breaking code if other values in your table change as would happen if your primary key was a compound of other column values.
- Ensure the uniqueness of each key within your table without locking or race conditions as auto-incremented IDs automatically avoid repetition and duplication.
- Improve system performance because they’re a compact data type, which allows for highly optimized code paths that avoid skipping between columns to create keys.
Additionally, primary keys can be used across many systems and drivers to support object-to-row mapping and database-system-agnostic operations.
Having said all of that, using an auto-incremented primary key isn’t appropriate for every use case. Read up on this before really jumping in.
If you’re starting from scratch, you’ll need to create a table in your database that’s set up to auto-increment its primary keys.
➞ PostgreSQL
When creating an auto-incremented primary key in Postgres, you’ll need to use SERIAL to generate sequential unique IDs. Default start and increment are set to 1.
The base syntax is:
1CREATE TABLE TableName (
2Column1 DataType SERIAL PRIMARY KEY,
3Column2 DataType,
4);
5When applied to our example inventory data set, table creation looks like:
1CREATE TABLE Inventory (
2item_number int SERIAL PRIMARY KEY,
3item_type varchar(255),
4item_category varchar(255),
5item_name varchar(255);
6This first step is pretty straightforward. Just be sure to mark your item number column as the PRIMARY KEY.
➞ MySQL
Auto-incrementing in MySQL is pretty similar to SQL Server, except you don’t manually include the starting value and integer value. Instead, you use the AUTO_INCREMENT keyword, which has a default start and increment value of 1.
The basic syntax for creating this table in MySQL is:
1CREATE TABLE TableName (
2COLUMN1 DataType AUTO_INCREMENT,
3COLUMN2 DataType,
4);
5In our example, here’s the table we’d want to create:
1CREATE TABLE Inventory (
2item_number int AUTO_INCREMENT PRIMARY KEY,
3item_type varchar(255),
4item_category varchar(255),
5item_name varchar(255);
6Like Postgres, you need to make sure that you’re using the PRIMARY KEY keyword for the column you want to generate your unique IDs from.
➞ SQL Server
In SQL Server, you’ll use the IDENTITY keyword to set your primary key (or item_number in our use case). By default, the starting value of IDENTITY is 1, and it will increment by 1 with each new entry unless you tell it otherwise.
To start, create a table. The basic syntax:
1CREATE TABLE TableName (
2Column1 DataType IDENTITY(starting value, increment by),
3Column2 DataType,
4);
5When applied to our inventory test case, table creation will look like:
1CREATE TABLE Inventory (
2item_number int IDENTITY(1,1) PRIMARY KEY,
3item_type varchar(255),
4item_category varchar(255),
5item_name varchar(255);
6Again—one last time—make sure to include PRIMARY KEY next to the SERIAL keyword, so you’re not just generating a useless list of sequential numbers.
Now, once you’ve created the framework of your table, you’ll need to decide if the default starting and increment values make sense for your use case.
Subscribe to the Retool monthly newsletter
Once a month we send out top stories (like this one) along with Retool tutorials, templates, and product releases.
Unless you’re building a new app from scratch, chances are you’ll be importing or working within an existing dataset. This means that you’ll need to adjust the starting point of your auto-increment to account for the existing values (and possibly the increment between values depending on naming conventions).
Working within our inventory dataset example, let's say you were migrating and updating the records from your first product release into a new table before adding new and improved products. For simplicity’s sake, let’s say your company just happens to have released 49 different items in the first go-round, which means you’ll need to start your new values at 50.
Also, for whatever reason (nobody documented it), your predecessors created past item_numbers in increments of five, so you’ll want to keep the vernacular correct and increment by five with each new product added. Thankfully, this change is easy to make in (just about) every DBMS.
➞ PostgreSQL
Postgres is kind of weird here: changing the auto-increment start and increment values in Postgres involves the ALTER keyword and requires you to create a custom SEQUENCE as a separate, single-row table that you’ll then insert into your employee table.
First, create a custom SEQUENCE using:
1CREATE SEQUENCE sequencename
2start 2
3increment 2;
4Note: make sure that this sequence name is distinct (i.e. doesn’t share the name of any other tables, sequences, indexes, views, or foreign tables within your existing schema) to avoid conflicts.
In our example, we want item_number to start at 50 and go up by five with each new value. The code for that would look like:
1CREATE SEQUENCE item_number_pk
2start 50
3increment 5;
4Then, you insert this record into the inventory table we created earlier and set the item_number value to this new item SEQUENCE like so:
1INSERT INTO Inventory
2(item_number, item_type, item_category, item_name)
3VALUES
4(nextval('item_number_pk'), 'Item Type', 'Item Category', 'Item Name');
5Each time you add a value to your table (see below), you’ll need to call out that the item_number value is:
1nextval('sequencename')
2If you’re only looking to change the starting value of your IDs (and not the increment value), you can just use ALTER SEQUENCE and save yourself some of the legwork. The basic syntax for this looks like:
1ALTER SEQUENCE project_id_seq RESTART [value];
2For our example, this looks like:
1ALTER SEQUENCE Inventory RESTART 50;
2➞ MySQL
If you’re using MySQL, you can run ALTER TABLE to set new auto-increment starting values. Unfortunately, MySQL doesn’t support changes to the default increment value, so you’re stuck there.
The basic syntax for this looks like:
1ALTER TABLE TableName MODIFY COLUMN value DataType AUTO_INCREMENT=50;
2Using our inventory table example, your adjustment to the auto-increment start value would be:
1ALTER TABLE Inventory MODIFY COLUMN item_number INT AUTO_INCREMENT=50;
2After running this code, future item IDs will start at an item_number of 50 and increment by 1.
➞ SQL Server
To change the starting increment value and increment in SQL Server, set your non-default values during table creation. Looking back at our base syntax from the previous section:
1CREATE TABLE TableName (
2Column1 DataType IDENTITY(starting value, increment by),
3Column2 DataType,
4);
5In our example, where we want item_number to start at 50 and go up by five with each new value, the code would look like:
1CREATE TABLE Inventory (
2item_number int IDENTITY(100,5) PRIMARY KEY,
3item_type varchar(255),
4item_category varchar(255),
5item_name varchar(255);
6If you’re looking to add auto increment to an existing table by changing an existing int column to IDENTITY, SQL Server will fight you. You’ll have to either:
- Add a new column all together with new your auto-incremented primary key, or
- Drop your old
intcolumn and then add a newIDENTITYright after
In the second scenario, you’ll want to make sure your new IDENTITY starts at +1 the value of the last id in your dropped column to avoid duplicate primary keys down the road.
To do this, you’d use the following code:
1ALTER TABLE Table DROP COLUMN old_id_column
2ALTER TABLE Table ADD new_auto_incremented_volumn INT IDENTITY(starting value, increment value)
3With our example, this would look like:
1ALTER TABLE Inventory DROP COLUMN old_item_number
2ALTER TABLE Inventory ADD item_number INT IDENTITY(50, 5)
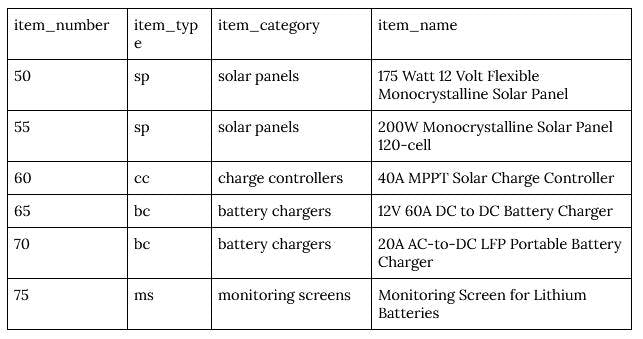
3Regardless of what DBMS you end up using, though, if you’re following along with our example scenario, your output should resemble the following table (MySQL notwithstanding since it doesn’t support non-default increments of 5). We’ll get into adding the values seen below in the next section.
Build internal tools on top of Postgres, MySQL, SQL Server, and dozens of other data sources with Retool: Assemble your app in 30 seconds by dragging and dropping from 50+ pre-built components. Connect to dozens of data integrations and anything with a REST or GraphQL API. Get started for free👉
The good news is that the syntax for adding values with auto-increment is the same for 2/3 of the DBs we’re discussing here. As expected, Postgres is the odd duck since it makes you mention your custom sequence as the value for your primary key with each new entry if you’re incrementing by more than 1.
But for the other two, it’s pretty straightforward. The nice part of auto-increment in SQL Server and MySQL is that you can set your primary key start point and forget about it. No need to refer back and manually add in that value when inserting info for the other columns.
To INSERT into your auto-incremented table, use:
1INSERT INTO TableName (FieldName1, FieldName2, FieldName3)
2VALUES ('Field1Value','Field2Value','Field3Value');
3For our example, let’s say you’re adding your new 175 Watt 12 Volt Flexible Monocrystalline Solar Panel (nice, by the way) to the system:
1INSERT INTO Inventory (item_type, item_category, item_name)
2VALUES ('sp','solar panels','175 Watt 12 Volt Flexible Monocrystalline Solar Panel');
3Then a few days later, after a big shipment makes it in, you need to add five more products simultaneously. You can truncate things by doing the following:
1INSERT INTO Inventory (item_type, item_category, item_name)
2VALUES ('sp','solar panels','200W Monocrystalline Solar Panel 120-cell'), ('cc','charge controllers','40A MPPT Solar Charge Controller'), ('bc','battery chargers','12V 60A DC to DC Battery Charger'), ('bs','battery chargers','20A AC-to-DC LFP Portable Battery Charger
3'), ('ms','monitoring screens','Monitoring Screen for Lithium Batteries');
4Note how, in the above examples, you don’t have to mention or INSERT values for item_number. That’s because our friendly neighborhood auto-increment is doing that for us.
The output of these new records into your inventory data table should look like this:
Auto-incremented primary keys are great but not always the right solution. Exposing your primary key externally – whether in a URL when referencing an employee profile or between your database and others – can open your system up to botnets and other vulnerabilities.
You can create more secure DBs (and improve recall speed) by using auto-increment to create your primary keys for internal, private use only and then create a separate UUID for public use by combining your primary key with a second value within your table, such as item_type. Doing this allows you to keep all the benefits of auto-incrementing both primary keys and public IDs while obfuscating your primary keys.
For our example solar panel manufacturer and reseller, our primary key is our auto-incremented unique id item_number, and our public-facing UUID (public_id) is a combination of that item_number and our item_type. This public-facing UUID is what customers will see on each product’s web page, what they can reference for issues and returns, and what will appear on their order invoices, while our primary key (item_number) is hidden and reserved for internal database use only.
To do this, your code—using our example and working with SQL Server as your DBMS—would look this:
1CREATE TABLE Inventory (
2item_number int IDENTITY(50,5) PRIMARY KEY,
3public_id varchar(10),
4item_type varchar(255),
5item_category varchar(255),
6item_name varchar(255);
7This would automatically create a unique item_number that starts at 50 and increases by five for each new value, and also create one new column—public_id—with a varchar data type that will serve as one-half of our UUID.
You’d then add in your product information—as we did in previous sections—with a concatenation of your item_number and public_id fields.
1INSERT INTO Inventory (item_type, item_category, item_name)
2VALUES ('sp','solar panels','175 Watt 12 Volt Flexible Monocrystalline Solar Panel'), ('sp','solar panels','200W Monocrystalline Solar Panel 120-cell'), ('cc','charge controllers','40A MPPT Solar Charge Controller'), ('bc','battery chargers','12V 60A DC to DC Battery Charger'), ('bs','battery chargers','20A AC-to-DC LFP Portable Battery Charger
3'), ('ms','monitoring screens','Monitoring Screen for Lithium Batteries');
4UPDATE Inventory SET public_id = concat(item_type, item_number);
5This code would result in the following output, now with an additional column for your public-facing item IDs.
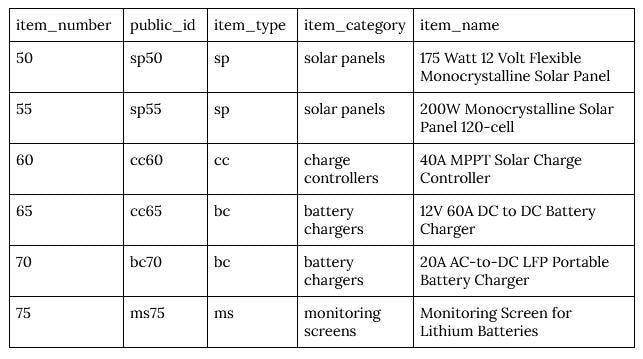
Once you’ve generated the above fields, you’re now able to reference your product information internally between apps and databases using your item_number primary key, as well as have a universally unique ID-public_id-that can be referenced by customers, accounting, and sales teams without compromising app security.
If you’re just here to CTRL+F your way to a solution (no judgment), you’ve come to the right section. Below is a quick and dirty breakdown of the syntax for each of the concepts discussed at length above.
PostgreSQL
1CREATE TABLE TableName (
2Column1 DataType SERIAL PRIMARY KEY,
3Column2 DataType,
4);
5MySQL
1CREATE TABLE TableName (
2COLUMN1 DataType AUTO_INCREMENT,
3COLUMN2 DataType,
4);
5SQL Server
1CREATE TABLE TableName (
2Column1 DataType IDENTITY(starting value, increment by),
3Column2 DataType,
4);
5PostgreSQL
1CREATE SEQUENCE sequencename
2start 2
3increment 2;
4Then insert this sequence into your main table:
1INSERT INTO TableName
2(Column1, Column2, Column3, Column4)
3VALUES
4(nextval('sequencename'), 'Value1', 'Value2', 'Value3');
5Or, if you’re just looking to change the starting value of IDs:
1ALTER SEQUENCE project_id_seq RESTART [value];
2MySQL
1ALTER TABLE TableName MODIFY COLUMN value DataType AUTO_INCREMENT=50;
2SQL Server
1CREATE TABLE TableName (
2Column1 DataType IDENTITY(starting value, increment by),
3Column2 DataType,
4);
51INSERT INTO TableName (FieldName1, FieldName2, FieldName3)
2VALUES ('Field1Value','Field2Value','Field3Value');
31CREATE TABLE Inventory (
2item_number int IDENTITY(50,5) PRIMARY KEY,
3public_id varchar(10),
4item_type varchar(255),
5item_category varchar(255),
6item_name varchar(255);
7Then insert your values and update your public-facing, external IDs to your concatenated values:
1INSERT INTO TableName (Column1, Column2, Column3)
2VALUES ('value1','value2','value3');
3UPDATE TableName SET new_public_id = concat(column1, auto-incremented-value);
4Using auto-increment is often a better way to create and manage values within your databases, no matter what DBMS you use. Doing so streamlines primary ID creation, improves database management by lowering retrieval times, and creates consistency among databases.
If you're looking for more SQL syntax help across dialects, check out our guide to formatting and dealing with dates in SQL.