If you’re building for the web, you’re probably spending a good chunk of your time working with REST APIs (or SOAP, if you’re really unlucky). The REST spec hasn’t changed much over the past two decades, but GraphQL has been stirring the pot. GraphQL is a query language for working with your data – built on top of your existing APIs – and it continues to rise in popularity since its open source release in 2015 because it makes building your app a lot easier.
When you write a GraphQL query, you declare exactly which objects and fields you need; GraphQL takes care of how to actually get that data from your APIs. For a lot of apps, this is completely transformative:
- You only receive the data you need. No more over-fetching data and sifting through large, complex objects.
- You only have to make one request. Stop pinging multiple endpoints to piece together your data.
- You don’t have to worry about type checking. Types are automatically built-in to the schema and map to Javascript objects.
Sidebar: Connecting Retool to a GraphQL API takes just a few minutes, and lets you to build user interfaces quickly on top of your own data.
GraphQL does have a steeper learning curve than your typical GET or POST request, but it’s emerging as a serious contender. Almost 40% of JS devs have used it and would use it again, and that number has been growing fast.
GraphQL is an open source query language (and runtime) that lets you fetch and manipulate data from existing databases and APIs. To best understand why GraphQL is a great alternative to pure REST queries, consider this example: Let’s say you want to build a blog that has users, posts, and followers. You’ve built a few APIs that let you read and write.
Example Objects
With REST, you would need to query three separate endpoints to get the information you need:
https://retool.com/users/<id>returns user data for a specific idhttps://retool.com/users/<id>/postsreturns all posts by a user with a specific idhttps://retool.com/users/<id>/followersreturns all followers of that user
Which yields:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26{ "user": { "id": "12345", "name": "Melanie", "email": "melanie@example.com", "birthday": "January 1, 1990", } } { "posts": [{ "id": "11111", "title": "GraphQL Ecosystem", "body": "If you write ...", "likes": 124, }] } { "followers": [{ "id": "67891", "name": "Vanessa", "email": "vanessa@example.com", "birthday": "January 2, 1990", }] }
The problem is that these endpoints interact: if you want to list followers for a group of users, you'd need to iterate through each user endpoint and then call the followers endpoint for each. That’s a lot of trips between the client and the server. And if parsing multiple responses weren’t frustrating enough, there’s also the issue of data overload. Let’s say you wanted to get the name of a specific user. Querying the user's endpoint with the id would return much more than just the user’s name: you’d get the entire user object, including email and birthday, which is unnecessary. This gets tedious as objects grow and have more nested data.
With GraphQL, you just define exactly what you need and the runtime takes care of the rest. There’s one endpoint on the GraphQL server that the client sends their request to, and the server uses resolver functions to return only the data that the client defined in their request – even if that requires traversing multiple internal endpoints.
From the example above, you would send just one query that included a schema spelling out the specific information you needed:
1 2 3 4 5 6 7 8 9 10 11query { User(id: '12345'} { name posts { title } followers { name } } }
The GraphQL server would then send a response with the data filled out in the requested format. In this response, you would get exactly the information that you needed for your application—the user’s name, the titles of their posts, and the names of their followers. Nothing more, nothing less.
Using GraphQL eliminates large data transfers that the client doesn’t need and helps alleviate load on the server because the client has to send only one request.
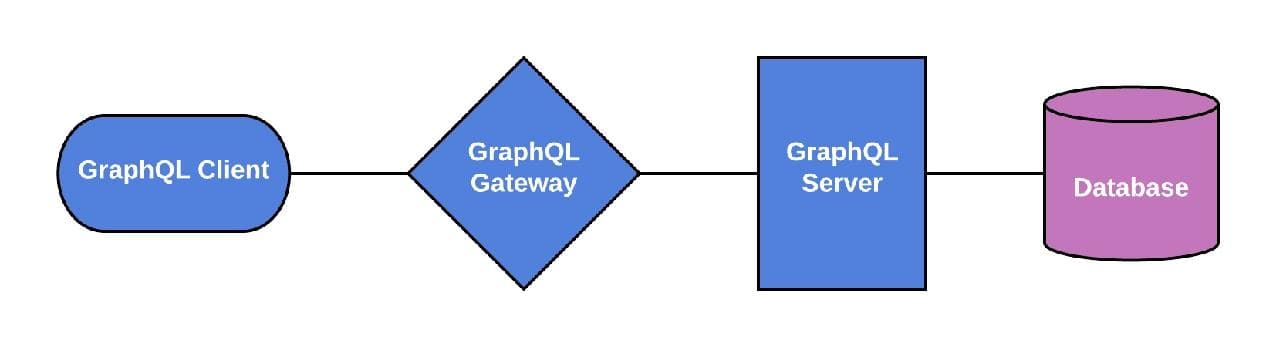
To get a fully functional GraphQL endpoint in place, you’ll need a client, server, and database, at the very least (if you’re reading this, you’ve probably got a few of these in place already). Gateways and additional tooling are helpful as well. But before you get started, there are a few things about working with GraphQL that you should be aware of.
Javascript and Typescript are the most common languages used with GraphQL and the majority of tools and software for the GraphQL ecosystem integrate best with them. If your codebase is in JS, great; if not, GraphQL can be used with almost any language and has support for Go, Ruby, and even Clojure. There are basically two ways to create APIs in GraphQL: schema-first and code-first.
Schema-first means that you first write out your schema with the different data types you’re using, and then you write the code that retrieves the data from the database (known as “resolver functions”). Using the example from earlier, in schema-first API building, you would begin by creating a schema:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30type: Query { posts: [Post] } type Post { title: String author: User body: String } type User { name: String posts: [Post] followers: [User] } And then writing resolver functions to follow: const resolvers = { Query: { posts: () => [] }, Posts: { title: post => post.title, body: post => post.body, author: () => {}, }, User: { name: user => user.name, followers: () => [], }, }
Because schema-first is the most common way to work with GraphQL, many of the popular applications in the ecosystem are set up to work this way. Apollo (a GraphQL implementation that includes a server, client, and gateway), for instance, supports a schema-first setup.
In code-first, you first write the resolver functions, and the schema gets auto-generated from your code. Building on the example above, a code-first approach would look like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27const Post = objectType({ name: "Post", definition(t) { t.string("title", { description: "Title of the post" }); t.string("body", { description: "Body of the post" }); t.field("author", { type: User, resolve(root, args, ctx) { return ctx.getUser(root.id).author(); }, }); } }); const User = objectType({ name: "User", definition(t) { t.string("name"); t.list.field("followers", { type: Person, nullable: true, resolve(root, args, ctx) { return ctx.getFollowers(root.id).followers(); }, }); } });
This saves time, but it is harder to learn when first getting started and is less supported by common GraphQL tools. Start by learning schema-first, and then work your way to the more advanced code-first (also known as “resolver-first”) method.
For more information about schema-first versus code-first approaches, check out this great guide from LogRocket.
The GraphQL client is how your frontend makes requests to your server. You can obviously write GraphQL queries directly in your frontend code, but client libraries take care of ergonomics and integrate cleanly with things like React Hooks. A good client library helps you do a few things:
- Retrieve schemas from the GraphQL server
- Build out their own request schemas based on the server schemas when making requests
- Send requests for data and connect that data to your frontend components
Apollo Client is one of the best-known client-side libraries for GraphQL because it’s JS-native, integrates easily with frameworks like React, and includes useful features like caching, pagination, and error handling. With the Apollo Client library, you can easily (well, more easily) develop for the web or mobile in iOS or Android.
The only work you have to do on the client side to use GraphQL is write the query and bind it to your component. The Apollo Client library handles requesting and caching data as well as updating the user interface.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27import React from 'react'; import { useQuery } from '@apollo/react-hooks'; import { gql } from 'apollo-boost'; const EXCHANGE_RATES = gql` { rates(currency: "USD") { currency rate } } `; function ExchangeRates() { const { loading, error, data } = useQuery(EXCHANGE_RATES); if (loading) return <p>Loading...</p>; if (error) return <p>Error :(</p>; return data.rates.map(({ currency, rate }) => ( <div key={currency}> <p> {currency}: {rate} </p> </div> )); }
In the code sample above (from the Apollo Client Get Started docs), we’re importing useQuery from the Apollo Client and using it as a React Hook to set state via our EXCHANGE_RATES query. There’s a lot of abstraction happening here, and the ability to set state with a React Hook directly from a query with the Apollo Client is pretty cool.
The Relay GraphQL client is built and maintained by Facebook Open Source — the same people who made GraphQL. It’s popular because it’s lightweight, fast, and easy to use. Also built in Javascript, the Relay library provides a React component called QueryRenderer that can be used anywhere in your React project, even within other containers and components.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45query UserQuery($userID: ID!) { node(id: $userID) { id } } // UserTodoList.js // @flow import React from 'react'; import {graphql, QueryRenderer} from 'react-relay'; const environment = /* defined or imported above... */; type Props = { userID: string, }; export default class UserTodoList extends React.Component<Props> { render() { const {userID} = this.props; return ( <QueryRenderer environment={environment} query={graphql` query UserQuery($userID: ID!) { node(id: $userID) { id } } `} variables={{userID}} render={({error, props}) => { if (error) { return <div>Error!</div>; } if (!props) { return <div>Loading...</div>; } return <div>User ID: {props.node.id}</div>; }} /> ); } }
In the code sample above (from Relay’s Quick Start Guide), users are being queried by userID, which is passed in as a variable to the React component. Relay’s QueryRenderer is used to send the GraphQL query and then render the returned data as either an Error, Loading, or the User ID.
Gateways aren’t necessary for a functioning GraphQL setup, but they can be a useful part of the ecosystem. Usually, they work as an addition to your GraphQL server or as a proxy service. The idea is to add adjacent services like caching and monitoring to improve performance.
Some common gateway features:
- Query caching to reduce the number of calls made to endpoints
- Error tracking via execution and access logs
- Trend analysis to get insight into changes in how your API is being used
- Query execution tracing to better understand end-to-end requests
All of this data can be used to track problems with your API, add improvements as performance data is collected over time, scale your app, and secure your platform. Apollo Engine is a widely used GraphQL Gateway that works nicely in GraphQL ecosystems, particularly if you are using Apollo Client and Apollo Server.
Your server is what enables all of that smooth frontend GraphQL code; it takes care of the ugly plumbing like handling queries via HTTP from your GraphQL client, retrieving the necessary data from the database, and responding to the client with the appropriate data following the client-defined schema.
The Apollo Server is one of the most commonly used servers for building APIs in GraphQL. It can be used as a fully functional GraphQL server for your project, or it can work in tandem with middleware like Express.js. While Apollo Server works best with the Apollo Client, it also integrates well with any GraphQL client and is compatible with all data sources and build tools.
GraphQL.js is Facebook’s Javascript reference implementation of GraphQL. Although most people only know of GraphQL.js as a reference, it is also a fully featured library that can be used to build GraphQL tools, like servers. The reason many don’t know about it is because there’s barely any documentation for it. The Apollo blog has a fantastic guide into the hidden features of GraphQL.js if you want to learn more.
Express-GraphQL is GraphQL’s library for creating a GraphQL HTTP server using Express. Express is lightweight, though it lacks some features like caching and deduplication. If you need a simple, fast, and easy to use library to create your GraphQL server, Express-GraphQL is a great option.
GraphQL works with pretty much any database that you can query with available clients (Postgres, Mongo, etc.). But if you want a database designed to work specifically with GraphQL, check out neo4j or Dgraph. Graph databases fit data into nodes and edges, which helps to emphasize the relationships between data points. Additionally, graph databases treat the data and connections between the data with equal importance.
As GraphQL has grown in popularity over the past five years, more tools have been added to the ecosystem to help make it easy to develop APIs in GraphQL. Start with ORMs, Database-to-GraphQL Servers, and IDEs when building out your GraphQL environment.
An Object Relational Mapper (ORM) is a type of library that lets you craft database queries in the language of your choosing. This is great because it abstracts away all interactions with the database (no SQL queries!) and lets you focus just on the language your program is written in. In the case of using GraphQL, an ORM lets you focus just on the GraphQL schema. There are numerous ORM tools like Sequelize and Mongoose, but if you’re looking for an ORM library to specifically integrate with GraphQL, TypeORM is your best bet.
Database-to-GraphQL Servers replace ORMs and keep developers from having to craft overly long and complicated SQL queries to get data from databases. Instead, SQL queries can be automatically generated based on simple API calls. One of the best tools for this is Prisma, which has a comprehensive and fully fleshed out GraphQL API.
IDEs (Integrated Development Environments) help complete the ecosystem by providing a place to, well, code. GraphQL-specific IDEs include GraphiQL and GraphQL Playground, which are soon to be combined into one powerful, fully featured IDE. You can also use API-building tools like Postman and Insomnia; they’re not meant for GraphQL specifically but have integrations to support it. Check out our guide to GraphQL IDEs to learn more.
Your personal GraphQL ecosystem should be built with the tools that make the most sense for your project and your experience. Remember, GraphQL is pretty new compared to other API specs (and is kind of a new idea in of itself), so there may be some bugs along the way. The GraphQL community is passionate and growing, which means new tools and best practices are evolving all the time.
Reader