They say that 70% of Data Science is moving data around and cleaning it. Unfortunately they’re wrong: 70% of Data Science and engineering is moving data around and cleaning it. We recently decided to move Retool’s community from Spectrum over to Discourse, and with hundreds of members and thousands of posts, there was a lot of moving to do.
You can jump ahead to the repo here.
Communities are all the rage in devtools these days (see Docker, Hugo, Atom, Rust, etc.). A lot of that is because developer products tend to be flexible: there are so many things that you can do with them that it’s impossible to support everything from scratch. Communities let users solve each other’s problems and share what they’re working on, which eases the support load and creates a more engaging product experience.
The most popular software powering these communities is called Discourse, and it’s from the founder of Stack Overflow. Most devtools “communities” are really forums where users can post about problems they’re running in to with the product or tasks they’re trying to accomplish. Other users (or staff) can jump in and reply. There’s basic markdown formatting, moderation features like badges and trust levels, as well as categories and tags for organizing posts.
Discourse is the most popular open source forum software out there, but it’s not the only one; the Retool community started out on an open source competitor called Spectrum. Spectrum is a little lighter-weight than Discourse out of the box, but over the past year it wasn’t really supporting our community’s needs as the volume of users and posts grew. In particular, we needed better search, tagging, user profiles and information, and gamification features.
The biggest challenge with any data migration is ergonomics: the schema of where you’re taking data from almost never matches that of where you’re sending data to. This project was no exception, as the Spectrum schema for storing posts was quite a trip to work with. The single biggest problem? Spectrum didn’t document anything about how data is stored or provide export utilities, so this entire project was pretty hacky.
Hierarchy and organization
In Spectrum, there are threads, messages, and channels (again, I had to figure this out by querying the underlying RethinkDB, not because Spectrum documented it):
- Threads are initial posts, like someone looking for help with an issue.
- Messages are replies to posts.
- Channels are collections of Threads and their Messages that map to a topic (#support, #showandtell, etc.).
Each message has an associated threadId that it belongs to, and each thread has a channelId that it belongs to.
Schemas
To write and store text, Spectrum uses a text editor framework built for React called DraftJS, and stores the data in a RethinkDB instance. The way that DraftJS actually stores the posts that you write in it is really difficult to work with programmatically. Here’s an example of how a thread gets stored – all examples in this post are from actual data that we used for the migration.
1 2 3""body"": ""{\""blocks\"":[{\""key\"":\""2q671\"",\""text\"":\""I want to dynamically load multiple rows from a Retool table + some data added from a JS query into a BigQuery table.\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""2s5av\"",\""text\"":\""The syntax for loading multiple rows into BQ is:\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""f53o\"",\""text\"":\""INSERT dataset.Inventory (product, quantity)\\nVALUES('top load washer', 10),\\n('front load washer', 20),\\n('dryer', 30),\\n('refrigerator', 10),\\n('microwave', 20),\\n('dishwasher', 30),\\n('oven', 5)\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""vek5\"",\""text\"":\""reference: https://cloud.google.com/bigquery/docs/reference/standard-sql/dml-syntax#insert_statement\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""en8ii\"",\""text\"":\""I'm triggering the BigQuery query from a JS query and passing 1 variable as additionalScope. I can't figure out what the format of the variable should be so that the BQ query accepts it. I have tried Array of Arrays and to convert the variable to a string accordingly:\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""bnalj\"",\""text\"":\""variable_array_of_array = [[\\\""front load washer\\\"", 20], [\\\""dryer\\\"", 30], [refrigerator\\\"", 10]]\\nor\\nvariable_string = \\\""((\\\""front load washer\\\"", 20), (\\\""dryer\\\"", 30), (refrigerator\\\"", 10))\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""6lsn5\"",\""text\"":\""I've had so many error messages when trying to solve this so I can't really refer to one error message that could give a clue on what the solution might be. I'm hoping that some of you might have an idea on how to solve this!\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}}],\""entityMap\"":{}}"", ""title"": ""Insert multiple rows into a table (BigQuery Resource - Query)""
Each message occupies its own JSON-like object, and any formatting (bold, italics, code) is attached to parts of the object as a descriptor with metadata about where it applies to. If we wrote a sentence with bold text in the middle, DraftJS would give you the sentence, and then where the bold appears, you’d see an inlineStyles parameter:
1 2 3 4 5 6 7 8#The whole post ""body"": ""{\""blocks\"":[{\""key\"":\""e4j8b\"",\""text\"":\""So I have an action on a table, but that action is disabled if the current row does not have some field set. So the disable logic is {{currentRow.foo === null }}. Now, when I go to filter the table, that action is always disabled. Even if the foo column has data in it.\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[{\""offset\"":133,\""length\"":28,\""style\"":\""CODE\""},{\""offset\"":243,\""length\"":3,\""style\"":\""CODE\""}],\""entityRanges\"":[],\""data\"":{}}],\""entityMap\"":{}}"", #The style descriptor \""inlineStyleRanges\"":[{\""offset\"":133,\""length\"":28,\""style\"":\""CODE\""},{\""offset\"":243,\""length\"":3,\""style\"":\""CODE\""}]
That format only applies to inline text decoration though; for images and links, DraftJS uses a completely different convention called entityRanges that get appended to the end of the whole post’s JSON. If your sentence has a hyperlink or an image in it, it gets marked with a placeholder and ID, which get referenced by the entities at the end of the object. If we wrote a sentence with a hyperlink in it, here’s how it would show up in the database:
1 2 3 4 5 6 7 8 9#The whole post ""body"": ""{\""blocks\"":[{\""key\"":\""52nge\"",\""text\"":\""I want to dynamically load multiple rows from a Retool table + some data added from a JS query into a BigQuery table.\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""1dfto\"",\""text\"":\""The syntax for loading multiple rows into BQ is:\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""2hb5i\"",\""text\"":\""INSERT dataset.Inventory (product, quantity)\\nVALUES('top load washer', 10),\\n('front load washer', 20),\\n('dryer', 30),\\n('refrigerator', 10),\\n('microwave', 20),\\n('dishwasher', 30),\\n('oven', 5)\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""bshrv\"",\""text\"":\""reference: https://cloud.google.com/bigquery/docs/reference/standard-sql/dml-syntax#insert_statement\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""b5t4e\"",\""text\"":\""I'm triggering the BigQuery query from a JS query and passing 1 variable as additionalScope. I can't figure out what the format of the variable should be so that the BQ query accepts it. I have tried Array of Arrays and to convert the variable to a string accordingly:\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""3q2o\"",\""text\"":\""variable_array_of_array = [[\\\""front load washer\\\"", 20], [\\\""dryer\\\"", 30], [refrigerator\\\"", 10]]\\nor\\nvariable_string = \\\""((\\\""front load washer\\\"", 20), (\\\""dryer\\\"", 30), (refrigerator\\\"", 10))\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""bjeib\"",\""text\"":\""I've had so many error messages when trying to solve this so I can't really refer to one error message that could give a clue on what the solution might be. I'm hoping that some of you might have an idea on how to solve this!!\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[],\""data\"":{}},{\""key\"":\""6qrdr\"",\""text\"":\""Skärmavbild 2020-02-03 kl. 19.36.14.png\"",\""type\"":\""unstyled\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[{\""offset\"":0,\""length\"":40,\""key\"":0}],\""data\"":{}},{\""key\"":\""faj7h\"",\""text\"":\"" \"",\""type\"":\""atomic\"",\""depth\"":0,\""inlineStyleRanges\"":[],\""entityRanges\"":[{\""offset\"":0,\""length\"":1,\""key\"":1}],\""data\"":{}}],\""entityMap\"":{\""0\"":{\""type\"":\""LINK\"",\""mutability\"":\""MUTABLE\"",\""data\"":{\""url\"":\""https://retool-spectrum.imgix.net/threads/draft/5f0acaee-55cd-4454-8a40-128c13bfb5ed-Ska%25CC%2588rmavbild%25202020-02-03%2520kl.%252019.36.14.png?expires=1578700800000&ixlib=js-1.2.1&s=ad4ed5a1bc24c38b928aa3ec28caa73b\""}},\""1\"":{\""type\"":\""IMAGE\"",\""mutability\"":\""MUTABLE\"",\""data\"":{\""src\"":\""https://retool-spectrum.imgix.net/threads/draft/26c4ca06-ffbc-4d3a-9214-11841239ae9d-Ska%CC%88rmavbild%202020-02-03%20kl.%2019.36.43.png\"",\""alt\"":\""Skärmavbild 2020-02-03 kl. 19.36.43.png\""}}}}"", ""title"": ""Insert multiple rows into a table (BigQuery Resource - Query)"" #The entityRanges section \""entityRanges\"":[{\""offset\"":0,\""length\"":1,\""key\"":1}],\""data\"":{}}],\""entityMap\"":{\""0\"":{\""type\"":\""LINK\"",\""mutability\"":\""MUTABLE\"",\""data\"":{\""url\"":\""https://retool-spectrum.imgix.net/threads/draft/5f0acaee-55cd-4454-8a40-128c13bfb5ed-Ska%25CC%2588rmavbild%25202020-02-03%2520kl.%252019.36.14.png?expires=1578700800000&ixlib=js-1.2.1&s=ad4ed5a1bc24c38b928aa3ec28caa73b\""}},\""1\"":{\""type\"":\""IMAGE\"",\""mutability\"":\""MUTABLE\"",\""data\"":{\""src\"":\""https://retool-spectrum.imgix.net/threads/draft/26c4ca06-ffbc-4d3a-9214-11841239ae9d-Ska%CC%88rmavbild%202020-02-03%20kl.%2019.36.43.png\"",\""alt\"":\""Skärmavbild 2020-02-03 kl. 19.36.43.png\""}}""
Both of these formatting descriptors use the same convention for identifying where the bold goes or where the images go: an offset value for where the styling starts, and a length value for how long it goes on for. Each unit is a character in the post string, so an offset of 18 means that the bold-ness starts 18 characters into the message.
This is all fine and dandy, except that Discourse isn’t built in React (it’s not even in Javascript!) and doesn’t use DraftJS. It uses Markdown.
Discourse’s schema is a bit simpler to parse: the API is clearly documented and, overall, returns useful responses with helpful information. Handling users was pretty easy, but topics and posts were where things got interesting.
Building a DraftJS → Markdown parser
Posting content through the Discourse API requires a raw payload, which corresponds to the content’s body, formatted in Markdown. We needed to translate the DraftJS data into Markdown, so we built a basic parser that iterated through all of the “blocks” in the DraftJS data structure and concatenated it into something that looks right in Discourse.
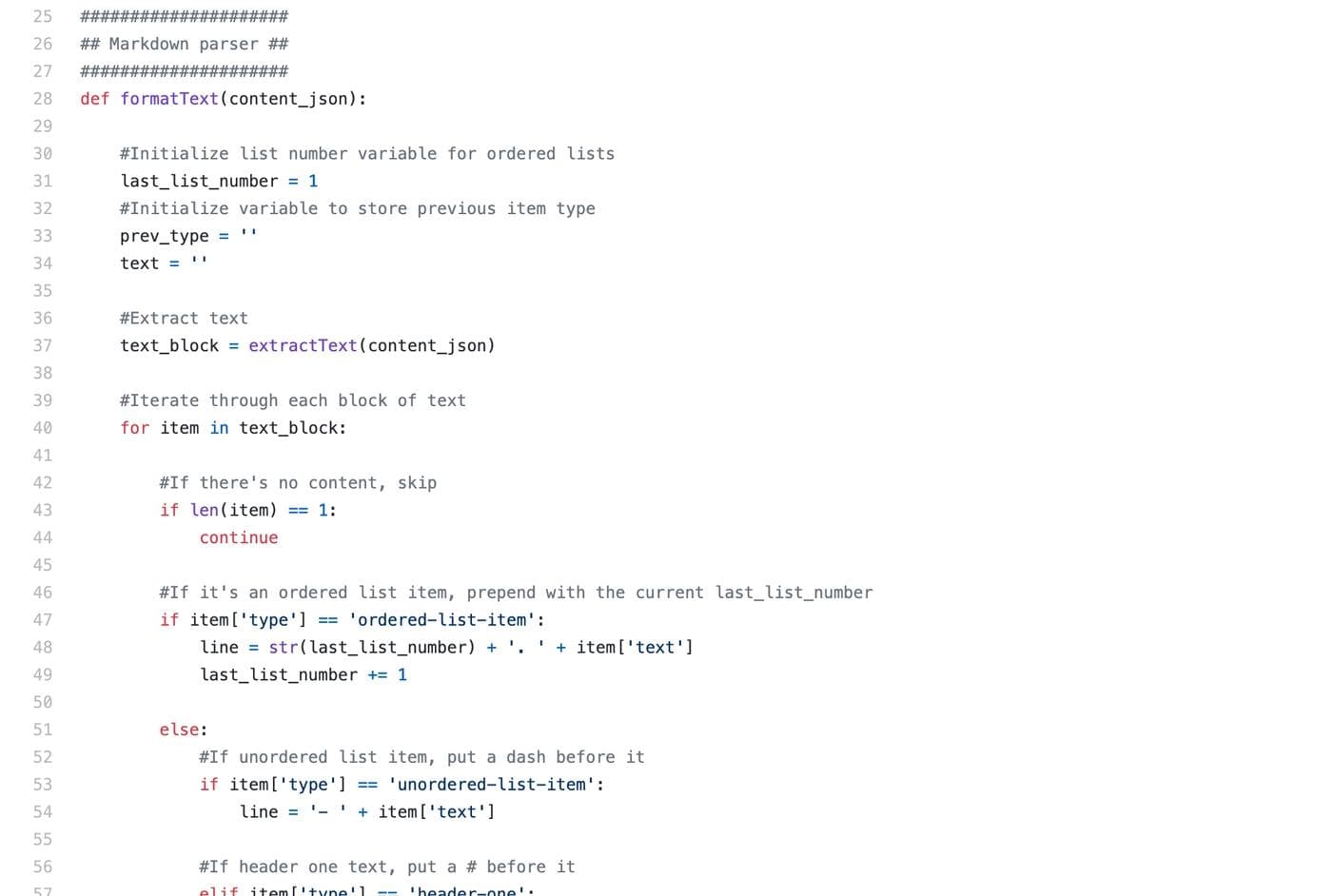
There are still some edge cases that this doesn’t account for: for example, if an entire message is a screenshot, the way that the RethinkDB stores the data doesn’t allow you to actually get the image URL, so the parser needed to just skip it.
The general workflow that we followed was to (1) export data from Spectrum, and then (2) iterate through it and post it all to Discourse via the Discourse API.
→ Users
Creating users: Users in the Spectrum RethinkDB were stored pretty intuitively, with properties like email and username. Discourse provides an endpoint for creating users, and we passed in the email, username, and name from Spectrum. For password we created a temporary one and asked users to change it when they signed in for the first time.
Post attribution: To make sure the migrated data looked smooth, we wanted all of the authors of topics and posts to be accurate: if user #1 created a topic in Spectrum, we wanted that topic to be attributed to the same user when it was moved into Discourse. The Discourse API endpoints for creating topics and posts don’t support this directly, but you can get around it via HTTP headers. Every time we created a new post or topic, we dynamically changed the HTTP headers of that request to use the username of whoever originally wrote the content.
→ Threads / Topics
Once we built the Markdown parser, all that was left to do was actually post the parsed threads / topics via the Discourse API. Discourse has a singular endpoint for both topics (“first posts”) and posts (“replies”): if you include a topic_id the backend reads it as a post (as a reply to that topic_id), and if you don’t, the backend reads it as a topic.
Because we set up our channels in Discourse differently than in Spectrum, we also needed to create a mapping layer that figured out which Spectrum channel a thread was originally part of, and which new Discourse channel that mapped to. Discourse provides a categories endpoint that lists your Discourse server’s categories (channels) and their associated IDs; we used that endpoint every time we posted a topic to find the appropriate category ID, and passed that category ID to the topics / posts endpoint to tell it where to post the topic.
→ Messages / Posts
The hardest part of the migration was handling posts (“replies”). To create a post via the Discourse API, you need to pass a topic_id that identifies which topic that post is replying to. That topic_id is created when you post the original topic and is a Discourse specific ID, so we needed to build a system for storing that topic_id when we created topics. Each message (post) in Spectrum had an associated threadId, so what we really needed was a way to map those Spectrum threadIds to the topics that they became in Discourse.
To keep things simple, we created a simple CSV file that lives in the migration directory and keeps track of which Spectrum threadIDs map to which Discourse topic_ids. Every time we created a new topic in Discourse via the API, it returns the topic_id that it generated; we stored that in the CSV in the same row as the original Spectrum threadId. Here’s what that file looked like:
1 2 3 4 5 6 7 8 9topic_id,discourse_topic_id,posts_posted 07f7d9a8-220b-4165-9729-e44b8cdd1fde,1727,True 07f7d9a8-220b-4165-9729-e44b8cdd1fde,1727,False 03534ad1-10aa-473f-9c5c-3a794ed9b78a,1728,True 188bce19-7150-4a81-9855-eeefd0f2d838,1729,True 0ccb2d63-a50d-4f7b-96a2-68997f9d24ec,1730,True 2a9f4bb7-5e7d-4439-ba9d-695ce46035c4,1731,False 24e85d2a-19f0-4df9-8eaf-637db2d5a447,1732,True 2beaac6b-8bbf-46fc-8b4d-ed51a7717293,1733,True
The last column is a boolean indicator of whether we had already created the posts attached to that topic in Discourse. Whenever a record gets created (when we created a new topic), that value gets set to FALSE, and updates to TRUE when we hit the posts endpoint for that topic_id. The reason we needed this in the first place was rate limiting, but more on that later.
To get these posts up on Discourse, we iterated through our topics CSV topic by topic:
- Filter posts data for posts about the current
topic_id - Order posts by
timestampand filter out bad data - Format post text (parse to Markdown)
- Create post via Discourse API attached to the right
topic_id - Mark the topic’s
posts_postedvalue asTRUE
This wasn’t quite perfect: we marked posts_posted as TRUE after the first post on that topic was created, not after all of them. So in theory if there was an error in the middle of creating all of the posts for a topic, data might get lost.
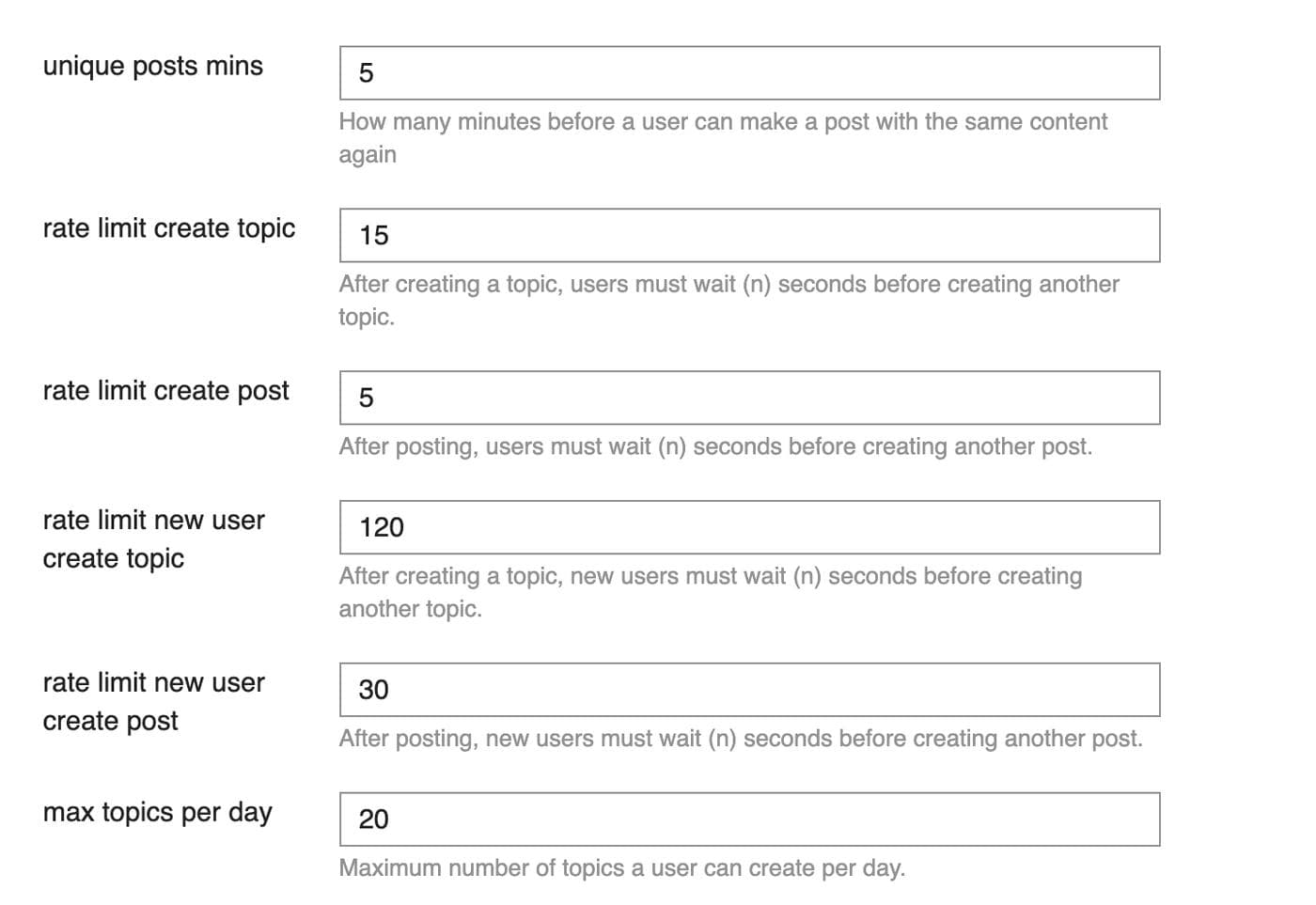
We weren’t dealing with very much data – around 400 topics or so in total – so this entire migration should have taken minutes once the scripts were written. Unfortunately, we ran into a huge issue: Discourse heavily rate limits their API even to Admin users. This makes a lot of sense product-wise, but was really inconvenient for our use case. Some specifics:
- Out of the box, Discourse severely rate limits the number of new posts and topics that any user (including admins) can create within a short timeframe
- Some of those settings are adjustable via the UI, but some are not and need command line fixes
- The API sometimes lags behind the application state and returns error messages like “this post already exists”
Here's what some of the Discourse rate limit settings look like:
It took a while to get a hang of exactly how to handle this, and there was a lot of manual limiting on our end (running the migration script on subsets of data). Eventually, we added a time.sleep() statement into our scripts that ran every time the API returned a rate limit error.
Like any data migration, some things went well and some didn't.
What worked:
- Community migrated!
When we started this project we weren’t sure if we were going to be able to get Spectrum data into Discourse at all. This was a huge win.
- Styling in Markdown!
Styling Discourse posts via the API was as easy as writing Markdown and using the simple parser that we built. After a bit of manual editing, the posts in our Discourse look great.
What didn’t work:
- Imperfect data
We weren’t able to get all Spectrum posts into Discourse perfectly – missing usernames, screenshots, and character limits made things a bit too complex. Thankfully we kept our Spectrum DB running, so we were able to manually refer back and fix a lot of these issues down the road.
- API limiting
Working with the Discourse API was a mixed bag. Rate limiting hurt our ability to migrate smoothly and created significant hurdles. Discourse’s Admin Web UI only allows you to remove certain limits, and some are hard coded in.
If you’re interested in the source code or you’re thinking of migrating from Spectrum to Discourse, we’ve open sourced the migration scripts we built. They’re pretty niche, but hopefully they’ll be helpful to someone one day 🙂. Pull requests welcome!
Reader